The Gate vs. The Guardrail
AI Governance in HUB Operations — Why Healthcare Keeps Building the Wrong Thing First.
Ankur Jain Esq.
3/16/20267 min read


ARTHA CONSULTING LAB · AI GOVERNANCE IN HUB OPERATIONS · ARTICLE 1 OF 4
The Gate vs. The Guardrail
A Governance Framework for AI Deployment in Specialty Pharmacy HUB Operations
Artha Consulting Lab · March 2026 · arthaconsultinglab.com
Across healthcare, artificial intelligence is being deployed in specialty pharmacy HUB operations at a pace that consistently outstrips the governance frameworks designed to manage it. This is not a technology failure. It is a sequencing failure — the gate is built before the guardrail.
Artha Consulting Lab's analysis of AI governance patterns across payer, specialty pharmacy, and HUB operations contexts identifies a repeating cycle: technology deployment precedes governance design, governance arrives as a remediation measure after the first material failure, and the window for proactive design narrows with each deployment.
This article presents a structured framework for AI governance in HUB operations — covering deployment classification, accountability architecture, escalation design, and dynamic governance maturity. It is the first in a four-article series.
The Deployment Pattern
Healthcare technology adoption follows a recognizable arc across three generations of HUB-adjacent technology:
Electronic Health Records (2010–2016) arrived with a promise of unified clinical data and decision support. Deployed primarily as documentation systems, they became compliance gates — increasing administrative burden without meaningfully improving clinical decision quality. Clinician burnout accelerated; limited decision support materialized.
Robotic Process Automation (2016–2022) promised administrative efficiency through rules-based automation. Deloitte research indicates only 3% of deployments scaled beyond 50 bots. The governance failure: rules-based systems require human oversight at every exception — a requirement that was rarely designed into deployment architecture.
Robotic General Automation and AI (2023–present) offer contextual reasoning, adaptive performance, and the potential for genuinely intelligent governance. The risk: the same deployment-before-governance pattern is already visible. Thirty-one percent of payers report a defined AI governance model. The remaining 69% are deploying without one.
The governance infrastructure that prevents gate formation must be designed before deployment — not assembled after the first adverse outcome.
Two Governance Failure Modes
Artha Consulting Lab's analysis identifies two distinct failure modes in healthcare AI governance. Both are predictable; both are preventable.
Failure Mode 1: The Over-Gate
The Over-Gate develops when governance design defaults to universal human review of all AI outputs, regardless of clinical risk or AI confidence. Characteristics include: PA turnaround times unchanged post-AI implementation; staff reviewing 95% or more of AI outputs; no defined auto-approval threshold for low-risk, high-confidence decisions.
Consequence: The AI investment generates no throughput improvement. Organizations operating in this mode frequently revert to manual-only processing, eliminating the operational case for AI while retaining the compliance and infrastructure costs.
Failure Mode 2: The Missing Rail
The Missing Rail develops when AI operates without defined escalation thresholds or accountability architecture. Characteristics include: no documented escalation triggers; AI decisions without audit trails; no defined human handoff protocol for low-confidence decisions.
Consequence: A single high-profile AI denial error generates regulatory exposure that cannot be defended — because the accountability chain was never built. This failure mode typically results in program suspension or shutdown.
The Accountability Architecture
A defensible AI governance framework requires a documented accountability chain for every AI-assisted decision. This chain comprises five links:
1. Data Input: Sources used, versions retrieved, timestamp recorded.
2. AI Processing: Output produced, confidence score, model version — all logged.
3. Human Review: Reviewer identity, scope of independent assessment, timestamp.
4. Decision: Final determination and decision owner. Decision accountability belongs to the human reviewer, not to the AI system.
5. Audit Record: Complete trail — data sources, AI version, reviewer identity, elapsed time, override status.
The legal and compliance value of this chain depends on the integrity of its weakest link. A reviewer who approves AI outputs without independent clinical assessment does not satisfy the human review requirement — and creates a documentation record that may actively undermine a compliance defense.
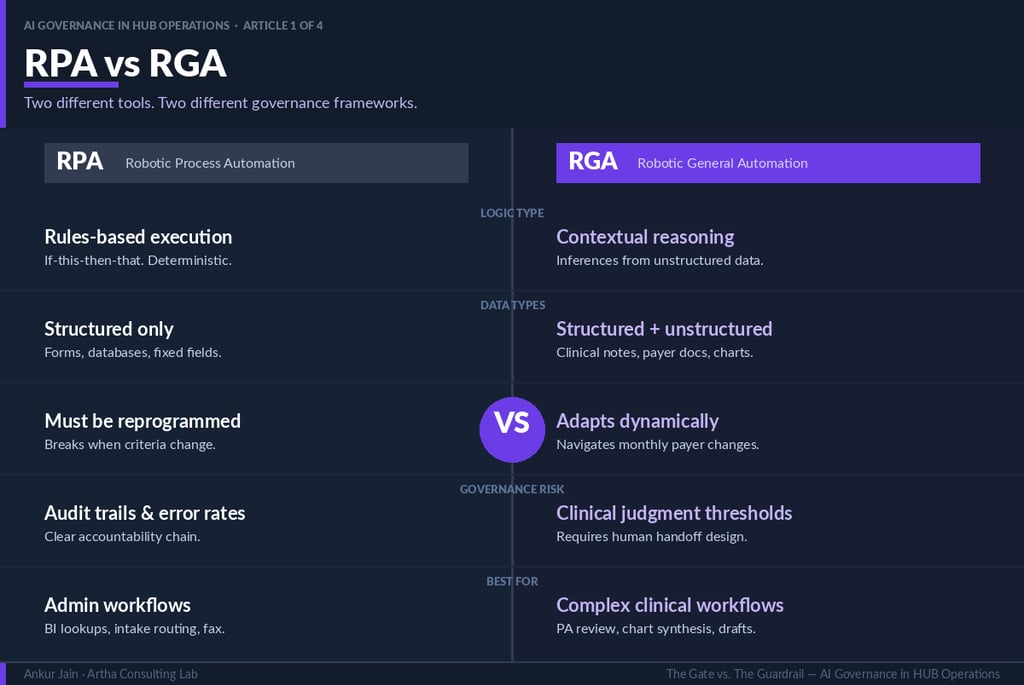
Governance Classification: RPA vs. RGA/AI
A material governance error common in HUB operations is the application of RPA governance frameworks to AI deployments. The tools differ fundamentally in their failure modes, and the governance requirements differ accordingly.
RPA governance addresses: deterministic logic errors, structured data processing failures, criteria-change responsiveness, and audit trail completeness for known decision paths. These are narrow, well-defined governance surfaces.
AI governance addresses: clinical judgment thresholds for AI-assisted interpretation, human handoff design for low-confidence decisions, escalation logic for clinical edge cases, and confidence-aware processing workflows. These are qualitatively different governance surfaces requiring different frameworks, different review competencies, and different audit architectures.
Organizations that apply RPA governance to AI deployments are not under-governed. They are incorrectly governed — which may be more dangerous.
The Four Governance Questions
Artha Consulting Lab recommends that every AI-assisted workflow in HUB operations be evaluated against four governance questions before deployment authorization. The answers determine the appropriate governance architecture for that specific workflow.
Question 1: Does this workflow involve clinical interpretation?
Administrative AI workflows (formulary retrieval, intake routing, co-pay processing) do not involve clinical interpretation and should not be governed as though they do. Clinical AI workflows (PA criteria matching, diagnosis appropriateness evaluation, clinical letter generation) involve clinical interpretation and require structured clinical review governance. Conflating these categories produces both over-governance of administrative workflows and under-governance of clinical ones.
Question 2: Is the patient situation novel, atypical, or high-acuity?
AI performance is most reliable on common presentations in well-represented populations. Rare disease diagnoses, pediatric patients, prior adverse event histories, and conflicting data presentations represent situations where AI training data is insufficient for reliable clinical inference. These situations require automatic human escalation — regardless of AI confidence output.
Question 3: Does the AI output enter a durable record or trigger clinical action?
AI-drafted content differs from AI-committed content. When AI output directly enters the medical record, drives dispensing decisions, or triggers patient-facing outreach, the stakes of an AI error increase materially. Human validation before commitment is required.
Question 4: What is the defined response to low AI confidence?
Most governance frameworks do not address this question. The consequence is silent processing failure — the AI continues to make decisions while operating below the confidence threshold at which those decisions are reliable. A guardrail framework defines specific confidence thresholds, fallback pathways, named reviewers, and SLAs for low-confidence resolution.
The Four-Quadrant Governance Framework
Based on the four governance questions, every AI-assisted workflow can be placed in one of four governance quadrants. Placement should be deliberate, documented, and subject to periodic review as AI performance evolves.
Quadrant 1: Full Automation
Criteria: Low clinical risk; high AI confidence. Governance model: aggregate-level monitoring; no per-transaction human review. Representative workflows: benefits investigation lookups, intake routing, co-pay enrollment processing.
Quadrant 2: Human Approves
Criteria: Medium clinical risk; medium-to-high AI confidence. Governance model: AI prepares; qualified human reviews and approves before clinical action. Review governance must define what the reviewer is required to independently verify. Representative workflows: PA package preparation, clinical letter drafting, denial identification.
Quadrant 3: Human Decides
Criteria: High clinical risk; variable AI confidence. Governance model: human owns the decision; AI surfaces data, drafts documentation, flags anomalies. AI informs; it does not recommend. Representative workflows: PA clinical review, nurse case management, complex appeals.
Quadrant 4: Human Only
Criteria: Highest clinical stakes; AI has no appropriate decision-making role. Governance model: hard boundary in system architecture. This boundary should be implemented at the system level — not only in policy documentation. Representative workflows: peer-to-peer clinical review calls, adverse event evaluation, urgent clinical need appeals.
Ten Mandatory Escalation Triggers
The following ten conditions require automatic human handoff in any AI-assisted HUB operations workflow. These triggers must be embedded in system architecture. Policy documentation that is not operationalized in system logic will not perform at the moment of need.
Clinical escalation triggers:
• Rare disease diagnosis
• Pediatric patient (age thresholds require explicit definition)
• Prior adverse event documented in patient record
• Conflicting clinical data across integrated data sources
• AI confidence below defined minimum threshold
Operational escalation triggers:
• Prior authorization denial determination
• Novel payer criteria pattern (criteria structure not previously processed by the AI)
• SLA risk condition with concurrent clinical flag
• Unavailable or incomplete data source
• Override request initiated by patient or clinical provider
Governance Maturity and Dynamic Frameworks
A governance framework designed at deployment and never updated is not a guardrail — it is a snapshot. AI performance evolves as models are updated, training data expands, and operational context shifts. Governance frameworks must evolve in parallel.
Artha Consulting Lab recommends quarterly governance review cadences that evaluate: AI performance against confidence thresholds for each quadrant; escalation trigger effectiveness (trigger rate, false positive rate, resolution quality); quadrant placement accuracy (are workflows still correctly classified?); and emerging regulatory requirements.
The organizations that build governance advantage are those that treat governance design as a continuous discipline — not a deployment prerequisite to be completed and filed.
The guardrail framework is not complete at launch. It is only beginning
About Artha Consulting Lab
Artha Consulting Lab advises specialty pharmacy manufacturers, HUB operators, and health plans on AI strategy, governance framework design, and compliance architecture. The AI Governance in HUB Operations series presents applied frameworks drawn from client engagements and regulatory analysis.