The Handoff Problem: Why HUBs Get Human-in-the-Loop Wrong
AI Governance in HUB Operations — Article 2 of 4. Human oversight in specialty HUB programs isn't failing because it's absent. It's failing because it's undifferentiated. Five questions that determine every handoff decision.
3/23/20267 min read


Specialty HUB programs operating with AI-augmented workflows face a structural governance challenge that industry vocabulary has so far obscured: the phrase 'human-in-the-loop' describes a control principle without specifying its application. Organizations deploying this language without workflow-level specificity are not operating governance frameworks — they are operating governance proxies.
The diagnostic question is not whether human oversight exists. It is which specific workflow decisions require human review before action is taken, what criteria trigger escalation, and who bears accountability when AI output passes review and still produces harm.
Across HUB programs in specialty pharma and health system patient access operations, two failure modes are consistently observed — and both operate under the banner of human-in-the-loop compliance.
Two Failure Modes in Human-in-the-Loop Governance
The first is the efficiency-first error: human review is nominal, reduced to a checkbox with no clinical weight. This failure emerges when deployment objectives are framed primarily as throughput improvement. Clinical staff reduce review to pattern confirmation; the AI functions as a production engine; the human checkpoint becomes a liability rather than a control.
The second is the risk-avoidance error: human review of every AI output regardless of decision type or risk profile. When review is universal, it becomes meaningless. Clinicians processing hundreds of AI outputs per day develop confirmation bias toward AI output — a dynamic well-documented in automation bias research. The failure mode is not negligence; it is a rational adaptation to a governance design that did not differentiate high-risk from low-risk decisions.
Neither configuration constitutes a governance framework. Both represent policy substitution for the harder analytical work: workflow-level decision architecture.
Why Undifferentiated Oversight Policies Fail
The appeal of uniform policy is administrative simplicity. The operational consequence is misallocated review capacity. The relevant governance distinction is not between clinical and non-clinical information — it is between clinical retrieval and clinical interpretation.
Formulary tier lookups and benefits investigation queries are data retrieval functions. Prior authorization clinical appropriateness determinations require the application of medical judgment to patient-specific data. These two functions share surface-level vocabulary but carry fundamentally different governance requirements.
Conflating clinical information with clinical interpretation is the root cause of most HUB governance failures observed in practice.
Eversana's digital HUB implementation demonstrates what differentiated governance produces in practice: 92% of benefit verifications completed in real-time through structured payer connectivity, with human case managers reserved for the 8% of complex exceptions the system surfaces for escalation. The governance design is explicit — AI handles retrieval; human judgment handles interpretation. The handoff is defined before deployment, not after.
Achieving that level of operational precision requires that five diagnostic questions be answered for every workflow type before AI deployment proceeds.
The Five Questions That Determine the Handoff
1. Does this workflow involve clinical interpretation?
Clinical interpretation is defined as the application of medical judgment to patient-specific data to reach a determination about clinical status, appropriateness, or risk. Benefits retrieval does not meet this definition. Prior authorization clinical review does. Workflows meeting this definition require mandatory human checkpoint prior to action.
2. Is the patient presentation novel, atypical, or high-acuity?
AI performance correlates with training data distribution. Atypical presentations — rare diagnoses, pediatric patients, prior adverse events, conflicting clinical data — represent distributional edge cases where AI error rates increase and error detection decreases. These cases require automatic escalation regardless of workflow classification.
3. Does the output enter a durable record or trigger a clinical action?
The governance boundary between AI drafting and AI committing is non-negotiable. Any output that enters the medical record, drives a dispensing decision, or triggers direct patient or provider outreach requires prior human validation. Yale New Haven Health System's Latent Health implementation operationalizes this boundary: AI drafts the PA request; a clinical pharmacist reviews and submits. The boundary does not move for throughput objectives.
4. Is the AI confidence signal calibrated for this patient population?
Human error rates in clinical AI oversight settings increase 12–17% when AI confidence exceeds 90%. Counterintuitively, high-confidence outputs suppress rather than improve oversight quality. Governance frameworks must specify minimum confidence thresholds for straight-through processing and must route low-confidence outputs — and outputs on underrepresented patient subgroups — to mandatory human review.
5. Does this output directly influence a coverage or care determination?
Prior authorization determinations are clinical events, not administrative ones. Any AI output that influences whether a patient receives specialty therapy — on time or at all — requires qualified human review before the organization's position is set. This obligation holds across benefit channels. The regulatory floor differs between pharmacy and medical benefit PA under CMS frameworks, but regulatory differentiation does not determine the clinical risk threshold for human oversight. Clinical risk governs.
Applying the Framework: Routing Architecture
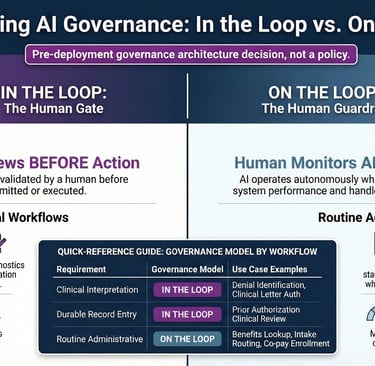
The five questions produce three governance routes for each workflow type: straight-through processing monitored at the aggregate level (on the loop); mandatory human checkpoint before action (in the loop); or automatic escalation to a clinical supervisor regardless of workflow classification.
Workflows where Questions 1, 3, or 5 resolve affirmatively are in-the-loop — no efficiency exceptions. Workflows where Questions 2 or 4 resolve affirmatively escalate regardless of other routing. All remaining workflows are on-the-loop, monitored for drift against defined error thresholds.
This is a governance architecture decision — not a technology configuration. It must be established before AI deployment and revisited with each model update and material regulatory change.
The routing architecture described here is not a policy overlay. It is a pre-deployment design decision that determines which workflows are AI-ready, what each is expected to produce, and what the human's precise role is in each. Organizations that approved AI deployment before completing this analysis have governance gaps that policy language will not close. That architecture — how to build, document, and maintain it durably across model changes and regulatory shifts — is the subject of Article 4 in this series.
In the Loop. On the Loop. Know the Difference.
Penn LDI's distinction between 'in the loop' and 'on the loop' provides the operational vocabulary this industry requires. In the loop: human review before action is taken. On the loop: human monitoring after the AI has acted.
Both configurations have legitimate applications in HUB operations. Benefits investigation, intake routing, and co-pay enrollment belong on the loop — monitored at the aggregate level for drift and error patterns, not reviewed transaction by transaction. Prior authorization clinical review, clinical letter authorization, and denial identification belong in the loop, with human validation of the specific output before it advances.
The in-loop or on-loop assignment for any given workflow follows directly from its data characterization: completeness, risk profile, and regulatory exposure. That assignment is a pre-deployment architecture decision. Governance does not get imposed on a workflow after the AI goes live. It gets designed in during the phase where workflow AI-readiness is assessed and output requirements are defined.
The governance failure Artha observes most consistently is not choosing the wrong configuration — it is defaulting to on-the-loop governance for decisions that require in-the-loop controls, and labeling that default an efficiency decision. Regulatory scrutiny of AI-assisted utilization management is increasing. Litigation risk follows.
A Third Failure Mode: Automation Bias
Two governance failures have been addressed in this analysis: absent human review, and universal review without differentiation. A third failure mode warrants separate treatment — and may present the highest risk profile of the three.
Automation bias describes the tendency of trained professionals working alongside AI systems to accept AI output without independent critical evaluation — not through negligence, but through rational adaptation to an environment in which the AI is usually correct. Human clinical judgment degrades through systematic disuse in workflows that no longer require it. Research published in 2026 characterizes this as 'moral deskilling': the progressive erosion of independent judgment in environments that reward speed and penalize the friction of independent evaluation.
This dynamic operates at the individual level as a form of authority displacement — the erosion of professional identity and decision-making authority in functions that previously defined clinical expertise. Artha has examined this pattern in the context of specialty HUB coordinator roles; a related analysis appears in a recent Hub Brief episode. When AI assumes decisions that previously constituted the core of a coordinator's expertise, the loss is not efficiency — it is professional authority. Governance frameworks that do not account for this dynamic will produce technically compliant oversight structures that erode the clinical judgment required to make that oversight meaningful.
Building the correct handoff architecture is necessary. It is not sufficient.
The behavioral dimension of AI governance in HUB operations — and the organizational interventions required to address automation bias at scale — is the subject of Article 3 in this series.
Operational Implications
Organizations achieving governance compliance in AI-augmented HUB operations share a common characteristic: they completed workflow-level decision architecture before deployment, not after. They mapped every AI-assisted workflow against a structured diagnostic framework, determined governance requirements at the workflow type level, and built oversight structures around those determinations.
That analytical exercise is not a technology project. It requires clinical, operations, and compliance leadership engaged at the workflow design level — answering the five questions for each workflow type before any AI output touches a patient record or influences a coverage determination.
More than half of specialty patient services programs are operating hybrid HUB models. The infrastructure for AI-augmented operations is broadly deployed. The governance frameworks that determine whether that infrastructure produces reliable clinical outcomes — or produces liability exposure — are not.
Governance begins with five questions. The organizations that have answered them are operating differently from those that have not.
About Artha Consulting Lab
Artha Consulting Lab advises specialty pharma manufacturers, patient access programs, and health system HUB operations on AI governance, workflow architecture, and operational compliance. This is the second article in a four-part series on AI governance in HUB operations.
Next: When the Governance Works and the Human Still Gets It Wrong — Automation Bias in HUB Operations
Article 4: Building the Governance Stack — How to Design, Document, and Audit AI Oversight in Specialty HUB Operations
Sources
Penn LDI — In the Loop or On the Loop: The Conundrum of AI Clinical Decision Support
Health Affairs (2025) — The AI Arms Race in Health Insurance Utilization Review
Drug Channels (Feb 2026) — The State of Patient Access: Hub Models, Technology, and the Road Ahead
Human Factors Research (2024) — Confidence-Induced Automation Bias in Clinical AI Settings
PMC / NIH — From Human-in-the-Loop to Human-in-Power
Henglong Dang (Medium, Mar 2026) — Why Decisions Matter More Than Intelligence
CHAI — Responsible AI Implementation Guide (RAIG)
Joint Commission + CHAI (2025) — Responsible Use of AI in Healthcare (RUAIH)
CMS — Interoperability and Prior Authorization Final Rule (CMS-0057-F)
Notable Health — More Than AI: How Human-in-the-Loop Connects Healthcare